
Python Scikit-learn简介
Scikit-learn概述
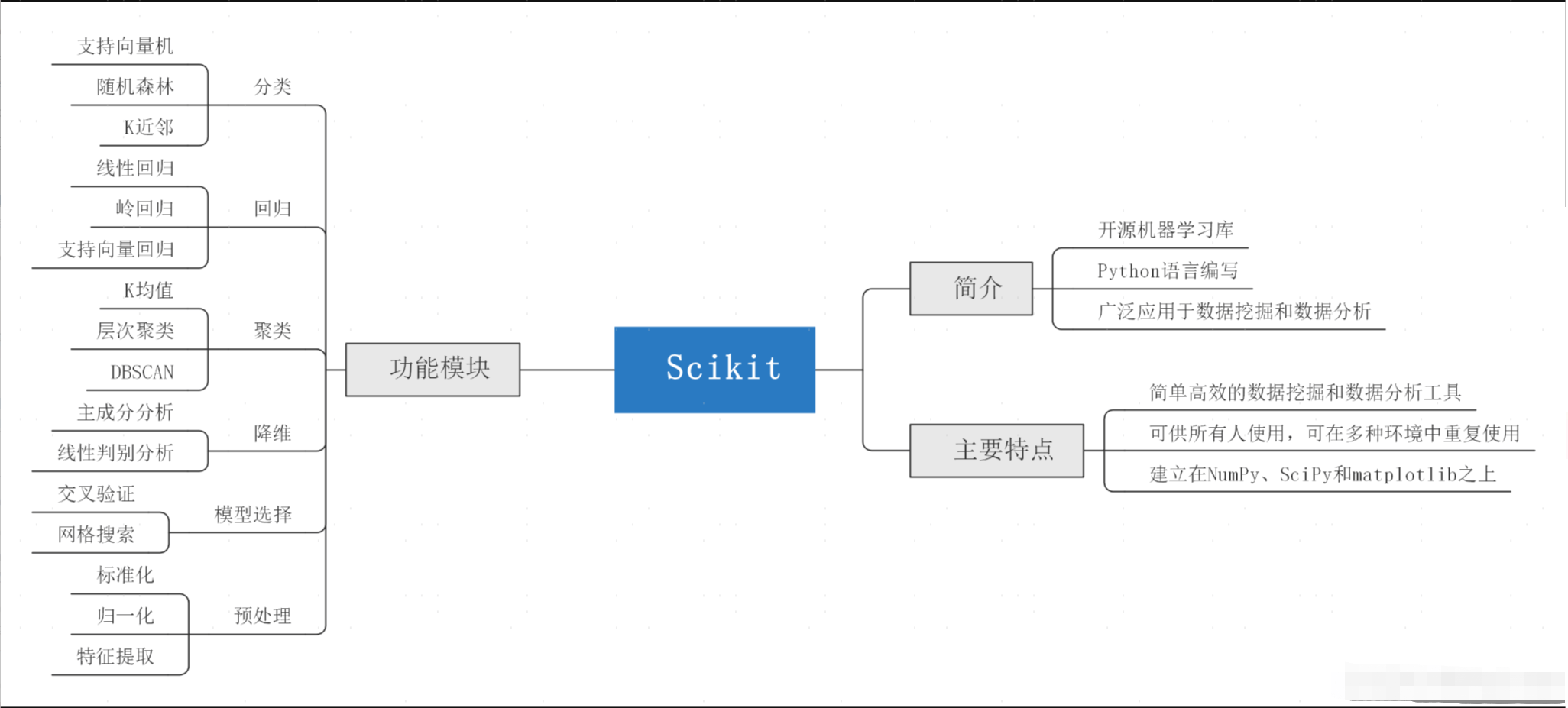
Scikit-learn是一个开源的Python机器学习库,它建立在NumPy、SciPy和Matplotlib之上,提供了大量的机器学习算法和工具,适用于各种机器学习任务,如分类、回归、聚类、降维等。Scikit-learn的设计遵循简洁、一致的API接口,使得用户可以轻松地从数据预处理到模型评估的整个机器学习流程中进行操作。它还提供了丰富的文档和示例,帮助用户快速上手和解决问题。

Scikit-learn的优点
数据集



数据预处理
StandardScaler。MinMaxScaler。SimpleImputer填充缺失值。OneHotEncoder或LabelEncoder。SelectKBest等方法选择最重要的特征。
StandardScaler 是 Python 中 scikit-learn 库提供的一个工具,用于对数据进行标准化处理。标准化(也称为Z-score标准化)是指将特征数据按比例缩放,使其符合标准正态分布,即均值为0,标准差为1。
使用公式 (x – μ) / σ 对每个特征值进行转换,其中 x 是原始特征值,μ 是均值,σ 是标准差
MinMaxScaler是数据预处理中的一种常用方法,主要用于数据的归一化处理。归一化是指将数据按比例缩放,使之落入一个小的特定区间,如[0,1]或[-1,1]
MinMaxScaler通过计算特征列的最小值和最大值来实现归一化,使得不同范围的数据特征具有相似的权重,确保在机器学习模型中各个特征的平等性。
MinMaxScaler的原理很简单,它使用下面的公式进行归一化:
X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0))
X_scaled=X_std*(max-min)+min
SimpleImputer的主要功能是将数据中的缺失值用指定的策略进行填充。这些策略可以是:
fill_value参数来设置。填充注意:
OneHotEncoder用于将具有多个离散值的特征转换为二进制编码的形式;它将每个离散值转换为一个二进制向量,其中只有一个元素为1,其余元素为0,表示该特征的取值。适用于处理具有多个类别的分类特征。常用于逻辑回归、决策树等机器学习算法中,以处理分类特征。
LabelEncoder用于将分类数据转换为数值标签;它将不同的类别映射到不同的整数值,使得分类数据可以被机器学习算法处理。适用于处理只有两个类别的二分类问题,或需要将多个类别映射为数值标签的场景。
SelectKBest是scikit-learn库中的一个特征选择类,它的主要作用是从一组特征中选择出对目标变量(如分类或回归的输出)影响最大的K个特征。
核心API概览
Scikit-learn的核心API围绕着三个主要组件:
估计器(Estimator)、转换器(Transformer)和预测器(Predictor)。
fit_transform方法结合了训练和转换。模型评估与选择
模型评估是选择最佳模型的关键步骤。Scikit-learn提供了多种评估工具和指标:

交叉验证
交叉验证是一种评估模型泛化能力的技术,通过将数据集分成多个子集,并在不同的子集上训练和验证模型。
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
# 加载示例数据
iris = load_iris()
X = iris.data
y = iris.target
# 初始化模型
model = LogisticRegression(max_iter=200)
# 使用K折交叉验证评估模型
scores = cross_val_score(model, X, y, cv=5)
print("Cross-validation scores:", scores)
print("Mean cross-validation score:", scores.mean())
超参数优化
超参数优化是寻找使模型性能最优的超参数组合的过程。Grid Search和Randomized Search是常用的超参数优化方法。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
# 加载示例数据
iris = load_iris()
X = iris.data
y = iris.target
# 初始化模型
model = SVC()
# 定义超参数搜索空间
param_grid = {'C': [0.1, 1, 10, 100], 'kernel': ['linear', 'rbf']}
# 使用Grid Search进行超参数优化
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X, y)
print("Best parameters:", grid_search.best_params_)
print("Best score:", grid_search.best_score_)
作者:凤枭香



