
Pycharm连接Hive数据仓库实操指南:Python端口实现对数据库的增删改查操作
本文的hive数据仓库采用HDFS作为底层数据存储,配置3台虚拟机搭建的分布式文件系统。
注意:虚拟机等配置是已经搭配好的,本文不是介绍配置环境,是介绍Pycharm连接Hive数据仓库,管理数据库的(看到这可以移步)。
pycharm安装所需库:pyhive连接安装所需库pip install PyHive thrift thrift-sasl;jdbc连接安装所需库pip install JayDeBeApi JPype1。如果少写了,根据所需自行安装对应库即可。
一、(方法1,界面查看)专业版的Pycharm连接Hive数据仓库。
1、专业版的提供一个工具Big Data Tools。借助这个工具可以直接配置连接,通过界面直观查看连接是否正常。记得先下载好对应的插件,这个工具正常下载的有点慢。(这个即使不配置也可通过命令和python编码连接,只不过通过界面看更直观明了)
2、配置端口连接,首先在配置HIve之前需要配置HDFS的连接。配置源的主机名称和端口是配置Hadoop的core-site.xml文件下的 <name>fs.defaultFS</name><value>hdfs://192.168.137.100:9000</value>这个参数里面的主机端口配置,有的配置教程里面可能用的是默认就没有变更或写入,不清楚就用默认端口,或查看其他配置文件是否有。一般设置是免密,配置HDFS尽量不要开启Kerberos,一般默认是没有开启的。用户名可以填主机名称,这个没要求。其他默认。配置好之后就可测试连接成功。失败原因一般是端口填错或启用了较为复杂的身份验证。

3、上述HDFS连接成功后就配置HIve。选择Hive Metastore,配置源是配置HIve时hive-site.xml文件中定义的<name>hive.metastore.uris</name><value>thrift://localhost:9083</value>这个参数配置。记得给localhost换成主机IP,防止误认为是Windows的主机(只要启用隧道正常可以不改,没啥影响)。

启用隧道是通过SSH连接访问到虚拟机,默认端口都是22。
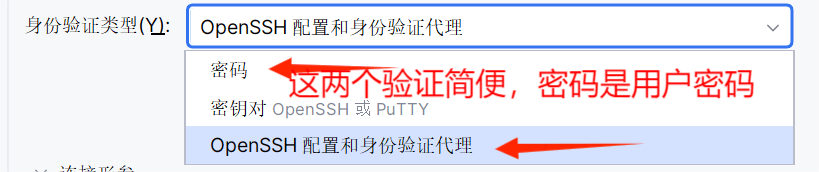
SSH测试正常连接,Hive Metastore就测试连接即可,到这就配置界面完成。连接失败原因一般是配置源的那个地方的端口写错导致的,查找Hive配置对应文件,如果没设置则添加配置。
二、(方法二)文章开始有提到所要安装的库,缺少的根据实际情况自行安装。运用pyhive库编码连接,访问查询数据库。这个所有的ip和端口是配置环境时所用的。HDFS webui界面默认端口9870,YARN webui界面默认端口8088。一般都是默认端口,根据实际配置情况填写自己配置文件中的端口。下面是python编码,专业版和社区版进行了对比测试,都支持。

1、上传到HDFS:
import csv
from hdfs import InsecureClient
#: 创建一个简单的 CSV 文件
local_file_path = 'C:/Users/Lenovo/Desktop/dataload/userdata.csv'
with open(local_file_path, mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
# writer.writerow(['id', 'username', 'password', 'role']) # 写入表头
writer.writerow([1, 'admin01', 'e10adc3949ba59abbe56e057f20f883e', 'admin'])
writer.writerow([2,'user01', '25d55ad283aa400af464c76d713c07ad', 'user'])
# 初始化 HDFS 客户端
client = InsecureClient('http://192.168.137.100:9870', user='root')
# 定义目标 HDFS 路径
hdfs_directory = '/user/cs_data.csv'
# 上传文件到 HDFS
try:
client.upload(hdfs_directory, local_file_path)
print(f"文件 '{local_file_path}' 已成功上传到 HDFS 目录 '{hdfs_directory}'")
except Exception as e:
print(f"发生错误:{e}")专业版运行:

这个是pycharm社区版的运行:

2、载入数据到Hive:
from pyhive import hive
#连接到 Hive
conn = hive.Connection(host='192.168.137.100', port=10000, username='hive')
# 创建一个 Hive 查询游标
cursor = conn.cursor()
# 查询当前数据库中的所有表
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
# 打印当前数据库中所有表
print("当前数据库中的表:")
for table in tables:
print(table[0])
# 如果表 test001 存在,先删除它
cursor.execute("DROP TABLE IF EXISTS test001")
# 创建表test001
cursor.execute("""
CREATE TABLE test001 (
id INT,
username STRING,
password STRING,
role STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
""")
# 载入 HDFS 上的数据文件 /user/cs_data.csv
cursor.execute("""
LOAD DATA INPATH '/user/cs_data.csv' INTO TABLE test001
""")
print(f"文件 /user/cs_data.csv 已成功加载到 'test001' 表")
print("当前数据库中的表:")
for table in tables:
print(table[0])
# 查询并验证数据是否已成功加载
cursor.execute("SELECT * FROM test001")
# 获取查询结果
results = cursor.fetchall()
# 打印查询结果
print("test001 表中的数据:")
for row in results:
print(row)
# 关闭连接
cursor.close()
conn.close()
print("表 test001 已创建并插入了数据")只要环境、端口啥的配置正确,无论是社区版还是专业版都可以通过python编码,管理数据库中的内容。

三、(方法三)JDBC连接。文章开始有提到所要安装的库,缺少的根据实际情况自行安装。jdbc端口是由 hive.server2.thrift.port 配置项在 hive-site.xml 中设置的。默认端口是 10000,如果需要修改,可以在 hive-site.xml 中指定新的端口并重启 HiveServer2 服务。建议将hive安装完成后出现的hive-jdbc-2.3.3-standalone.jar驱动文件复制到本地一个位置方便调用(是复制驱动文件到Windows中的一个位置方便后续调用,如果编程软件是在虚拟机里面可直接路径调用)。(个人感觉jdbc在python中使用时需要添加详细的用户和密码,否则就会报错,没有pyhive调用方便;但是,支持端口调用的编译软件都支持此方法,兼容性强大。)
import jaydebeapi
# 配置 Hive JDBC 驱动的路径
jdbc_driver_name = "org.apache.hive.jdbc.HiveDriver"
# jdbc_driver_loc = "/path/to/hive-jdbc-<version>-standalone.jar" # 实际的 JDBC 驱动路径
#hive-jdbc-2.3.3-standalone.jar
jdbc_driver_loc = "C:/Users/Lenovo/Desktop/hive-jdbc-2.3.3-standalone.jar" # 实际的 JDBC 驱动路径
# 设置 JDBC 连接字符串
jdbc_url = "jdbc:hive2://192.168.137.100:10000/default" # HiveServer2 地址
username = "hive"
password = "111111" # 如果没有密码,则为空字符串
# 建立 JDBC 连接
conn = jaydebeapi.connect(jdbc_driver_name, jdbc_url, [username, password], jdbc_driver_loc)
# 创建一个 Hive 查询游标
cursor = conn.cursor()
# 封装查询并打印表数据的函数
def query_and_print_table(cursor, table_name):
cursor.execute(f"SELECT * FROM {table_name}")
results = cursor.fetchall()
# 将所有数据格式化成一行输出
print(f"{table_name} 表中的数据: ", end="")
print(", ".join([str(row) for row in results]))
# 查询当前数据库中的所有表
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
# 打印当前数据库中所有表
print("当前数据库中的表:")
for table in tables:
print(table[0])
# 如果表 test0001 存在,先删除它
cursor.execute("DROP TABLE IF EXISTS test0001")
# 创建表 test0001
cursor.execute("""
CREATE TABLE test0001 (
id INT,
name STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
""")
print("表 test0001 已创建")
#1、增加数据
#插入 5 条数据到 test0001 表
cursor.execute("""
INSERT INTO TABLE test0001 (id, name, age)
VALUES
(1, 'Alice', 25),
(2, 'Bob', 30),
(3, 'Charlie', 22),
(4, 'David', 28),
(5, 'Eva', 35)
""")
print("5 条数据已插入到 test0001 表")
# 查询并验证数据是否已成功插入
query_and_print_table(cursor, "test0001")
# 添加新的一条数据 (id = 6)
cursor.execute("""
INSERT INTO TABLE test0001 (id, name, age)
VALUES (6, 'Frank', 30)
""")
print("添加了 id 为 6 的新数据")
# 查询并验证数据是否已成功修改
query_and_print_table(cursor, "test0001")
#2、删除数据
# 删除第四条数据 (id = 4)
cursor.execute("""
INSERT OVERWRITE TABLE test0001
SELECT id, name, age
FROM test0001
WHERE id != 4
""")
print("删除了 id 为 4 的数据")
# 查询并验证数据是否已成功修改
query_and_print_table(cursor, "test0001")
#3、变更数据
# 更新第五条数据,将 id 为 5 的数据的 id 改为 7
cursor.execute("""
INSERT OVERWRITE TABLE test0001
SELECT
CASE
WHEN id = 5 THEN 7
ELSE id
END AS id,
name, age
FROM test0001
""")
print("更新了 id 为 5 的数据,将其 id 改为 7")
# 查询并验证数据是否已成功修改
query_and_print_table(cursor, "test0001")
#4、查询数据
cursor.execute(f"SELECT * FROM test0001 WHERE age = 30")
results = cursor.fetchall()
print(f" test0001 表中 age 为 30 的数据:")
for row in results:
print(row)
# 关闭连接
cursor.close()
conn.close()
print("表 test0001 已创建并修改数据")
四、简单测试:pyhive连接数据库(缺少的库根据实际情况自行安装),通过端口设置连接数据库,管理数据库文件,创建文件并进行增删改查。

from pyhive import hive
# 连接到 Hive
conn = hive.Connection(host='192.168.137.100', port=10000, username='hive')
# 创建一个 Hive 查询游标
cursor = conn.cursor()
# 封装查询并打印表数据的函数
def query_and_print_table(cursor, table_name):
cursor.execute(f"SELECT * FROM {table_name}")
results = cursor.fetchall()
# 将所有数据格式化成一行输出
print(f"{table_name} 表中的数据: ", end="")
print(", ".join([str(row) for row in results]))
# 查询当前数据库中的所有表
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
# 打印当前数据库中所有表
print("当前数据库中的表:")
for table in tables:
print(table[0])
# 如果表 test0001 存在,先删除它
cursor.execute("DROP TABLE IF EXISTS test0001")
# 创建表 test0001
cursor.execute("""
CREATE TABLE test0001 (
id INT,
name STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
""")
print("表 test0001 已创建")
#1、增加数据
#插入 5 条数据到 test0001 表
cursor.execute("""
INSERT INTO TABLE test0001 (id, name, age)
VALUES
(1, 'Alice', 25),
(2, 'Bob', 30),
(3, 'Charlie', 22),
(4, 'David', 28),
(5, 'Eva', 35)
""")
print("5 条数据已插入到 test0001 表")
# 查询并验证数据是否已成功插入
query_and_print_table(cursor, "test0001")
# 添加新的一条数据 (id = 6)
cursor.execute("""
INSERT INTO TABLE test0001 (id, name, age)
VALUES (6, 'Frank', 30)
""")
print("添加了 id 为 6 的新数据")
# 查询并验证数据是否已成功修改
query_and_print_table(cursor, "test0001")
#2、删除数据
# 删除第四条数据 (id = 4)
cursor.execute("""
INSERT OVERWRITE TABLE test0001
SELECT id, name, age
FROM test0001
WHERE id != 4
""")
print("删除了 id 为 4 的数据")
# 查询并验证数据是否已成功修改
query_and_print_table(cursor, "test0001")
#3、变更数据
# 更新第五条数据,将 id 为 5 的数据的 id 改为 7
cursor.execute("""
INSERT OVERWRITE TABLE test0001
SELECT
CASE
WHEN id = 5 THEN 7
ELSE id
END AS id,
name, age
FROM test0001
""")
print("更新了 id 为 5 的数据,将其 id 改为 7")
# 查询并验证数据是否已成功修改
query_and_print_table(cursor, "test0001")
#4、查询数据
cursor.execute(f"SELECT * FROM test0001 WHERE age = 30")
results = cursor.fetchall()
print(f" test0001 表中 age 为 30 的数据:")
for row in results:
print(row)
# 关闭连接
cursor.close()
conn.close()
print("表 test0001 已创建并修改数据")注意:运行成功的前提是HIve和HDFS是配置成功、正常的,且已知端口数据,明白如何进行端口调用。失败的原因一般是端口设置有问题或没有配置好。(本文使用的软件版本为jdk-8u202-linux-x64.tar.gz、hadoop-3.2.0.tar.gz、apache-hive-2.3.3-bin.tar.gz、mysql-5.7.33-1.el7.x86_64.rpm-bundle.tar(mysql Ver 14.14 Distrib 5.7.33, for Linux (x86_64) using EditLine wrapper
)、pycharm-professional-2023.2、PyCharm Community Edition 2023.2.1、CentOS-7-x86_64-DVD-2207-02.iso、python版本可自行安装(所需库暂没指定版本,可自行安装所需版本))
作者:2401_85045610

